
Wie funktioniert prädiktive KI?
Im Gegensatz zur generativen KI ist die prädiktive KI eine spezielle Form der künstlichen Intelligenz. Mit generativer KI – wie ChatGPT – kannst Du Inhalte erstellen. Mit prädiktiver KI kannst Du Vorhersagen treffen, die auf der Berechnung von Wahrscheinlichkeiten basieren.
Um zukünftige Ergebnisse oder Trends vorherzusagen, verwendet prädiktive KI historische Daten, Algorithmen und maschinelle Lernmodelle. Dabei werden Muster in bestehenden Datensätzen analysiert und auf zukünftige Szenarien extrapoliert. Wie das funktioniert und was Du davon hast, wollen wir herausfinden.
Was kannst Du mit prädiktiver KI im Marketing erreichen?
Für Marketer ist prädiktive KI ein entscheidender Faktor. Die Kernaufgabe eines jeden Marketers besteht darin, seine Zielgruppe(n) zu verstehen. So kann die Nachfrage nach Produkten oder Dienstleistungen gesteigert und letztendlich mehr Umsatz erzielt werden. Prädiktive KI kann bei all diesen Aufgaben helfen:
Kundenverhalten vorhersagen
Durch vorausschauende KI erhält man Einblicke in die Kundenbindung und kann gute Churn-Analysen erstellen. Du kannst Kaufgewohnheiten wie Bestellwert und Kaufhäufigkeit anhand der von der KI verwendeten Modelle vorhersagen. So bekommst Du die Informationen, die Du benötigst, um Deine Zielgruppe in sinnvolle und effektive Segmente aufzuteilen.
Kampagnenoptimierung
Mithilfe von vorausschauender KI kannst Du Deine A/B-Tests und die Optimierung der von Dir verwendeten Kanäle verbessern. Vorausschauende KI kann z.B. dabei helfen, den Zeitpunkt einer Kampagne festzulegen, an dem eine Reihe bezahlter Anzeigen am wirkungsvollsten ist.
Lead Scoring und Segmentierung
Mit Informationen über potenzielle zukünftige Conversions kann vorausschauende KI-Leads klassifizieren und Informationen für eine sinnvolle Segmentierung liefern.
Dynamische Preisgestaltung
Die Anpassung der Preise an die Nachfrage nach Produkten und Dienstleistungen ist für viele Unternehmen von Interesse. Wie sich die Nachfrage entwickeln wird, lässt sich vorhersagen. Dann können die Preise zum richtigen Zeitpunkt angepasst werden. Vorausschauende KI macht dies möglich.
Inhalte personalisieren
Vorausschauende KI ist besonders nützlich für Empfehlungssysteme. Vor allem große Unternehmen nutzen sie. So arbeitet Amazon zum Beispiel mit Empfehlungen für die richtige Kleidergröße. Diese basieren auf dem Stil und der Markenwahl der Kundinnen und Kunden. Das liegt einfach daran, dass nicht jede Kleidungsmarke dieselbe Größentabelle verwendet. Und wenn man sich als Kunde für ein bestimmtes Kleidungsstück entscheidet, kann man über Bewertungen und Kommentare von anderen Kunden erfahren, ob es sinnvoll ist, das Kleidungsstück eine Nummer größer oder kleiner zu bestellen. Die Kunden lieben das.
Diese intelligenten Formen der Personalisierung nutzt aber auch ein Unternehmen wie Netflix. Wir wollen ein Beispiel nennen. Es macht deutlich, was mit prädiktiver KI möglich ist.
Beispiel für vorausschauende KI anhand von Netflix
Netflix möchte viele Zuschauer auf seiner Plattform haben. Glücklicherweise sitzen die Marketer von Netflix auf einer Goldgrube an Daten. Schließlich sind die Vorlieben der Kunden öffentlich zugänglich. Netflix nutzt diese Daten intelligent. Durch den Einsatz von prädiktiver KI werden die Empfehlungssysteme von Netflix personalisiert. Doch wie sieht das in der Praxis aus?
Gleiche Empfehlung, aber personalisiert
Basierend auf bereits gesehenen Filmen, dem Fokus auf bestimmte Schauspieler und den Vorlieben für bestimmte Filmgenres personalisiert Netflix Filmplakate:

Diese intelligente Empfehlungstechnologie wird von Netflix verwendet, um mehr Kunden für diesen bestimmten Film oder diese bestimmte Serie zu gewinnen. Die Macht der prädiktiven KI wird hier sehr gut veranschaulicht.
Welche Daten braucht prädiktive KI?
Typen und Arten von Daten, die Du verwenden kannst
Dass die Vorteile der prädiktiven KI nur dann zum Tragen kommen, wenn Deine Daten in Ordnung sind, sollte sich von selbst verstehen. Schließlich werden die Prognosen auf der Basis historischer Daten erstellt. So etwas wie dynamische Preisgestaltung wird schwierig, wenn Du keine Preisentwicklungen und Kaufzeitpunkte in Deinen Systemen speicherst. Und wenn Netflix Filmplakate personalisiert: Dann musst Du speichern, wie oft welcher Kunde welche Art von Film am liebsten sieht.
Es hängt also von Deinem Unternehmen und vor allem davon ab, was Du mit vorausschauender KI erreichen willst, welche Daten Du für vorausschauende KI benötigst.
Daten, die Spotler in seinem Prädiktive-KI-Modul verwendet
Unsere Kunden sollen mit unserer Software Geld verdienen und Geld einsparen. Den Customer Lifetime Value (CLV) effektiver zu machen ist daher unser Fokus. Die dafür benötigten Datenpunkte sind customer_id, transaction_timestamp, invoice_id, item_number und order_type. Diese Daten werden in ein spezielles statistisches Modell eingespeist, das von Data Scientists häufig zur Prognose von Auftragswerten und Transaktionshäufigkeiten verwendet wird.
Wir verwenden auch das Random Forest Modell. In dieses Modell fließen nicht nur die genannten Daten ein, sondern unter anderem auch das E-Mail-Verhalten und die Interaktionen auf der Website.
Unten findest Du eine kurze Erklärung zu beiden Modellen. Das gibt Dir eine gute Einführung in prädiktive KI und wie sie funktioniert.
Wie kann der CLV mit prädiktiver KI verbessert werden?
Um einen Einblick in die zukünftige Entwicklung des CLVs eines Kunden zu bekommen, beginnt man mit den folgenden historischen Daten: die Anzahl der Käufe, die ein Kunde bei Dir getätigt hat, der Bestellwert jedes Kaufs und der Zeitpunkt des letzten Kaufs. Dieses Modell wird auch RFM-Modell genannt. RFM steht für Recency, Frequency und Monetary Value.

Der CLV errechnet sich aus dem Kundenwert (basierend auf RFM) multipliziert mit der durchschnittlichen Kundenbeziehungsdauer. Aus dem historischen Kundenverhalten lässt sich die durchschnittliche Dauer berechnen. Diese Berechnung gibt keinen Aufschluss über zukünftige Entwicklungen und ist deterministisch. Aber sobald man seine CLVs kennt, kann man damit beginnen, die Fragen zu stellen, die man wirklich wissen möchte:
- Wie viele Transaktionen werden z.B. im nächsten Monat stattfinden?
- Welche Kunden werden in diesem Zeitraum kaufen?
- Welchen durchschnittlichen Bestellwert kannst Du pro Kunde erwarten?
Mit diesem Wissen kannst Du tolle Marketingkampagnen entwickeln.
Mit CLV-Daten Vorhersagen treffen
Du machst eine Vorhersage über mögliches zukünftiges Verhalten, wenn Du die drei oben genannten Fragen beantworten willst. Um das tun zu können, brauchst Du ein mathematisches Modell, das das für Dich berechnet. Um es kurz zu machen: Das Modell mit der besten Erfolgsbilanz ist das BG/NBD-Modell mit einer Gammaverteilung der Daten (GG-Modell).
BG/NBD + GG Modell steht für Beta Geometric / Negative Binominal Distribution + Gamma Submodel. Das hört sich sehr kompliziert an, aber was man wissen muss, ist, dass es sich dabei um ein Modell zur Berechnung von Wahrscheinlichkeiten handelt. Das Modell ist noch nicht sehr alt. Es wurde 2005 von Fader, Hardie und Lee entwickelt. Eine kurze Erklärung:
Vorhersage der Anzahl von Transaktionen mit dem BG/NBD-Modell
Die komplizierte Abkürzung des Modells wurde von englischsprachigen Marketingspezialisten und Forschern auf „Buy Till You Die“ reduziert. Dabei wird die mögliche Anzahl der Transaktionen innerhalb einer vorgegebenen Zeitspanne berechnet. Zum Beispiel: Wie viele Transaktionen wird es im nächsten Monat geben? Oder aber auch: Welche Kunden werden im kommenden Monat etwas kaufen?
Das Modell ist „negativ binomisch“. Das liegt daran, dass man, wenn man weiß, welche Kunden im kommenden Monat etwas kaufen werden, auch weiß, welche Kunden im kommenden Monat nichts kaufen werden. Außerdem hast Du mit Sicherheit eine Reihe von Kunden, die nicht mehr kaufen oder seit Monaten inaktiv in Deiner Datenbank sind (das ist der „bis-Du-stirbst“-Teil).
Wenn Du all diese Informationen über aktive und inaktive Kunden in das BG/NBD-Modell einfügst, erhältst Du einen Einblick in die Kunden, die wahrscheinlich abwandern werden, in die Kunden, die am ehesten einen Kauf tätigen werden und in die Häufigkeit, mit der sie einen Kauf tätigen werden.

Vorhersage des durchschnittlichen Auftragswerts mit dem GG-Modell
Mit Hilfe des GG-Modells lässt sich auch der durchschnittliche Bestellwert pro Kunde vorhersagen.
Zur Erinnerung: Beim GG-Modell wird der gesamte Bestellwert jedes Kunden betrachtet und dieser Wert dann zufällig auf die Gesamtzahl der Transaktionen verteilt. Dadurch kann der durchschnittliche
Bestellwert von Periode zu Periode variieren. Abschließend erfolgt eine Verteilung des durchschnittlichen Auftragswertes über alle Kunden.
Einfacher ausgedrückt: Man erhält eine Vorhersage des durchschnittlichen Bestellwerts pro Kunde, indem man den durchschnittlichen Bestellwert aller Kunden mathematisiert.
Spotler verwendet das BG/NBD + GG-Modell
Wie Du gelesen hast, wird das Prädiktive-KI-Modell von Spotler mit RFM-Daten gefüttert. Wir verwenden das BG/NBD + GG-Modell auch für CLV-Vorhersagen.
Welche Machine Learning Modelle ermöglicht vorausschauende KI?
Neben der Verwendung des BG/NBD + GG Predictive Modells verfeinern Unternehmen die Ergebnisse, indem sie das E-Mail-Verhalten, Interaktionen auf der Website, Reaktionen auf saisonale Promotions, Teilnahme an Events etc. berücksichtigen.
Es ist durchaus möglich, dass ein Kunde aufgrund der Anzahl der Transaktionen einen geringen Score erzielt, aber trotzdem viel auf der Internetseite surft und an der letzten Veranstaltung teilgenommen hat. Wenn auch diese Daten berücksichtigt werden, wird jede Vorhersage besser. Dafür gibt es verschiedene KI-Modelle.
Beispiele für maschinelle Lernmodelle für prädiktive KI
In der prädiktiven KI gibt es verschiedene Modelle des maschinellen Lernens. Beispiele sind Gradient Boosting Machines wie XGBoost, Logistische Regression, Recurrent Neural Networks (RNN) und Random Forest. Wenn wir alle diese Modelle in einem einzigen Artikel erklären würden, wäre er in etwa so lang wie eine Doktorarbeit. Aus diesem Grund werden wir uns auf Random Forest konzentrieren, weil Spotler selbst dieses Modell verwendet.
Man muss bedenken, dass generative KI-Modelle als Ergebnis eine Wahrscheinlichkeitsberechnung liefern. Wenn ein Kunde jeden Monat genau einen Artikel bei Dir kauft, kannst Du davon ausgehen, dass er dies auch im nächsten Monat tun wird. Die Wahrscheinlichkeit ist hoch, aber sie ist kein Gesetz. Das Ergebnis ist nicht determiniert.
Der Unterschied zwischen deterministisch und probabilistisch
Die Modelle der Künstlichen Intelligenz sind von Natur aus probabilistisch und nicht deterministisch. Einfacher ausgedrückt: KI-Modelle berücksichtigen den Faktor „Unsicherheit“ in ihren Vorhersagen. Menschen machen jeden Tag das Gleiche, wenn sie Entscheidungen treffen. Sehr oft sind es unvollständige und unsichere Informationen, auf denen diese Entscheidungen beruhen.
Wir haben sogar ein schönes Wort dafür: Intuition. Und mit „Denken + Fühlen = Wissen“ gibt es sogar eine Gleichung. KI-Modelle haben keine Gefühle, aber sie sind probabilistisch. Wir baten Chi Shing Chang, den Geschäftsführer von SPARQUE.AI, zu einem Statement.
Der Unterschied zwischen deterministisch und wahrscheinlichkeitstheoretisch
“Stellen wir uns vor, Du hast eine Tierhandlung und möchtest Deinen Kunden ein zielgerichtetes Angebot machen. In einem deterministischen Modell sagst Du: Jedem Besucher, der die Kategorie ‚Hunde‘ besucht, wird eine E-Mail mit einem Angebot für seinen Hund geschickt. Was passiert aber, wenn ein Besucher mehrere Kategorien besucht? In einem probabilistischen Modell wird dies berücksichtigt: Es werden Wahrscheinlichkeiten berechnet. Ein Beispiel: Das Verhalten des Besuchers lässt sich zu 60 % in Hunde, zu 25 % in Katzen, zu 10 % in Vögel und zu 5 % in Nagetiere unterteilen. Wenn man ein gutes Angebot für Katzenbesitzer und nicht für Hundefreunde hat, kann man einem Besucher mit obigem Suchverhalten trotzdem etwas Relevantes senden.”
Chi Shing Chang, SPARQUE.AI
Wie funktioniert das statistische Modell Random Forest?
Sieh Dir die folgende Tabelle an:
| Kunden- ID | Letzter Kauf | Käufe auf das Jahr gerechnet | Durch-schnitt | Anz. Geöff. E-Mails | Anz. E-Mails-Klicks | Promo |
|---|---|---|---|---|---|---|
| 100 | 13-12-2024 | 10 | 15 | 6 | 4 | winter |
| 101 | 09-10-2024 | 2 | 70 | 3 | 2 | october |
Nehmen wir an, man möchte zum 1. Januar 2025 prognostizieren, welcher der beiden Kunden mit den Kundennummern 100 und 101 mit hoher Wahrscheinlichkeit innerhalb der nächsten 30 Tage wieder etwas kauft. Wie würdest Du vorgehen? Wahrscheinlich würde man Entscheidungsbäume erstellen. Vielleicht nicht im wörtlichen Sinne, aber zumindest in Deinem Kopf. Visuell kannst Du Dir das so vorstellen:
Entscheidungsbäume aufstellen
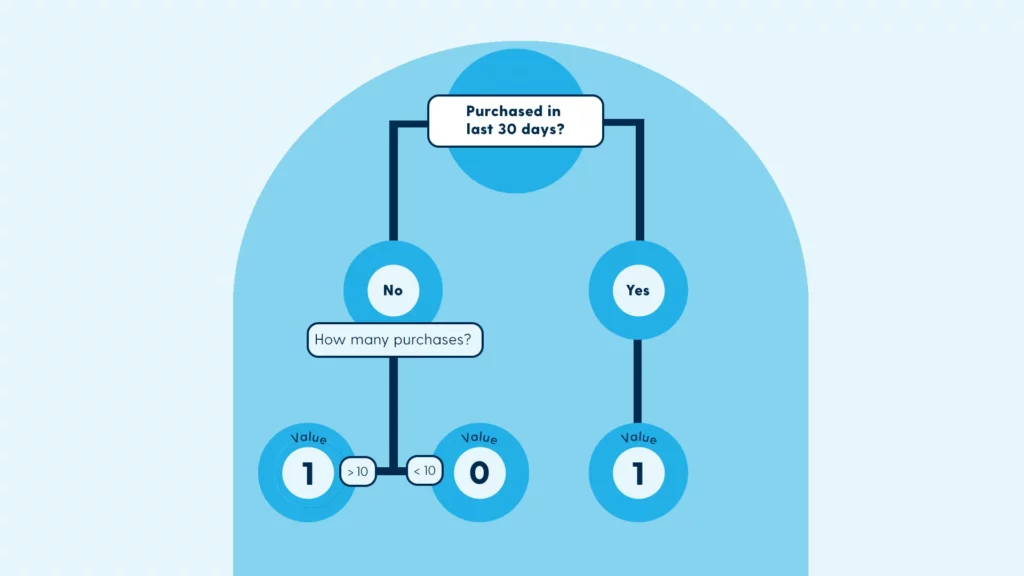
Auf der Grundlage dieses einfachen Entscheidungsbaums könnte man vorhersagen, dass alle Kunden mit einem Wert von 1 wahrscheinlich innerhalb von 30 Tagen einen weiteren Kauf tätigen werden. Das ist natürlich keine Garantie; ein solcher Entscheidungsbaum kann um mehrere Entscheidungspunkte erweitert werden, und Datensätze auf der Grundlage mehrerer Entscheidungsbäume können komplex werden. Bevor man sich versieht, hat man einen ganzen Wald von Entscheidungsbäumen. Nicht umsonst heißt das KI-Modell Random Forest.
Aber wozu braucht man einen ganzen Wald? Das hängt mit einem wichtigen Teil des KI-Modells zusammen: der Bootstrap-Aggregation. Das braucht eine kleine Erklärung.
Bootstrap aggregation
Als Bootstrap-Aggregation wird eine statistische Methode bezeichnet, mit der Du Daten sammeln kannst. Stell Dir einfach eine Gruppe von Musikern vor, die zusammen in einem Orchester spielen. Nur ein Musiker, zum Beispiel ein Oboist, spielt seinen Teil des Musikstücks. Anhand nur eines Instruments wäre es schwierig, das Musikstück zu erraten. Wenn mehrere Musiker ihren Part in dem Musikstück spielen, wird eine solche Vorhersage einfacher (oder genauer).
Auf der Suche nach einem neuen Auto… 🚗
Szenario 1:
Du suchst ein neues Auto und fragst einen guten Freund, welches Auto das Richtige für Dich ist. Er sagt: „Kauf den neuen Ford Explorer“. Wie wahrscheinlich ist es, dass Du jetzt in den Ausstellungsraum rennst?
Szenario 2:
Du bist auf der Suche nach einem neuen Auto und stellst einem guten Freund ein paar Fragen:
- Kannst Du mir ein paar gute Autos empfehlen, die meinen finanziellen Möglichkeiten entsprechen?
- Empfiehlst Du mir den Kauf eines Neuwagens oder Gebrauchtwagens?
- Welches Auto ist Deiner Meinung nach am besten ausgestattet?
- Welches Auto bringt nach 150.000 km den höchsten Wiederverkaufswert?
- Welche Automarken haben die umfangreichste Garantie?
- Welche Automarken sind am wartungsfreundlichsten?
Nachdem Du alle Antworten in Betracht gezogen hast, kommst Du zu dem Schluss, dass der Kauf eines neuen Ford Explorer die beste Option ist. Ist die Kaufwahrscheinlichkeit bei Szenario 2 größer oder kleiner als bei Szenario 1? Genau: viel größer. So funktioniert, vereinfacht gesagt, die Bootstrap-Aggregation.
Warum ist Bootstrapping ein guter Prädiktor?
In der Bootstrap-Aggregation werden aus dem ursprünglichen Datensatz Teilmengen erzeugt. Oder, wie im Autobeispiel, aus der Hauptfrage werden Unterfragen gebildet. Jede Teilmenge enthält die gleiche Datenmenge wie der ursprüngliche Datensatz. Möglicherweise enthalten die verschiedenen Teilmengen sogar dieselben Daten. Denn der neue Ford Explorer muss mit mehreren Baugruppen ausgestattet werden.
Eine solche Teilmenge wird auch als Bootstrap-Stichprobe bezeichnet. Diese Stichproben werden zufällig aus der Ausgangsmenge entnommen. Daher der Name „Random Forest“. Das ist eine sehr leistungsfähige Technik. Ohne sich auf Hypothesen verlassen zu müssen, können statistische Vorhersagen gemacht werden.
Natürlich wurde die Zuverlässigkeit dieser Methode getestet. Ein gutes Beispiel dafür ist ein Test, bei dem das Modell die Bodenbedeckung auf einem Stück Land in Colorado, in den Vereinigten Staaten, vorhersagen sollte. Das Modell wurde mit Daten wie der Anzahl der Sonnenstunden, dem Vorhandensein von Wasser usw. gefüttert. Random Forest erzielte eine Trefferquote von 94%.
Wie trainiert sich vorausschauende KI selbst?
Wie die generative KI hat auch die prädiktive KI die Eigenschaft des Selbstlernens bzw. Selbsttrainierens. Die Frage ist natürlich, wie das für ein Modell wie Random Forest aussieht.
Um eine prädiktive KI zu trainieren, werden die Daten in Trainings- und Testgruppen aufgeteilt. Zum Beispiel 80% Training und 20% Test. Mit den Testdaten werden dann die Trainingsdaten überprüft. Zur Erklärung:
Wie trainiert sich vorausschauende KI selbst?
Unser Wissen über die Welt
Stell Dir vor, Du willst vorhersagen, wie hoch die Temperatur am 28. Dezember 2025 in der Stadt Liverpool sein wird. Wie machst Du das? Zunächst einmal weißt Du, dass es Dezember ist und nicht mitten im Sommer. Du weißt, dass Liverpool in Großbritannien liegt. Und Du weißt, wie warm es heute ist. Dass Du letztes Jahr am 28. Dezember im Peak District gezittert hast, weißt Du auch. Um es kurz zu machen: 5 Grad Celsius ist eine vernünftige Schätzung.
Was ein Modell lernen muss
Als Menschen greifen wir auf eine große Menge an Wissen über die Welt zurück, um Vorhersagen treffen zu können. Ein KI-Modell hat dieses Wissen nicht, braucht es aber. Die von Menschen automatisch hergestellte Verbindung zwischen „Anfang Dezember“ und „kälter als im Hochsommer“ muss von einem Modell der Künstlichen Intelligenz erlernt werden. Das geschieht, indem die historischen Daten des Trainingsdatensatzes (z.B. Temperaturen zu verschiedenen Zeitpunkten) mit „1=ja“ oder „0=nein“ oder „wahr“ oder „falsch“ für das gewünschte Ergebnis ausgewertet werden: „Welche Temperatur wird am 28. Dezember 2024 herrschen? Mit vergleichbaren Daten (Testset) werden dann die Entscheidungsbäume getestet, die letztendlich zum richtigen Ergebnis führen.
Das KI-Modell hat keine Ahnung, dass es mit „Temperatur“ arbeitet. Als numerische Daten werden „weltliche“ Daten eingegeben (z.B. Klicks in einer E-Mail oder die Temperatur in Liverpool). Würde man das KI-Modell mit der Frage „Wie wird das Wetter in Manchester am 28. Dezember 2025 sein?“ arbeiten lassen, müsste das KI-Modell alles neu berechnen, während wir Menschen in der Lage sind zu sagen: „Es wird nicht viel anders sein als in Liverpool“.
Mit anderen Worten: Menschen lernen durch Erfahrung und Wissen über die Welt, und ein Modell der prädiktiven KI lernt durch das Testen von Entscheidungsbäumen. Natürlich: Ein KI-Modell kann mit vielen Daten rechnen, was letztlich dazu führt, dass es besser vorhersagt, als wir Menschen mit unserem Weltwissen vorhersagen können.
Ergebnis des Prädiktive-KI-Modells: Wahrscheinlichkeitsrechnung
Als Ergebnis des Präditktive-KI-Modells wird eine Wahrscheinlichkeitsrechnung durchgeführt. Für jeden Kunden sagt das Modell voraus, mit welcher Wahrscheinlichkeit er innerhalb der vorgegebenen Zeitspanne zu kaufen beabsichtigt. Eine mögliche Ausgabe des Modells könnte wie folgt aussehen:
| Kunden-ID | Kaufwahr- scheinlichkeit (30 Tage) | Kaufwahr- scheinlichkeit (60 Tage) | Kaufwahr- scheinlichkeit (90 Tage) |
|---|---|---|---|
| 100 | 85% | 92% | 98% |
| 101 | 20% | 50% | 65% |
Die Wahrscheinlichkeitsberechnung reicht – theoretisch – von 1% bis 100%. Die prozentuale Einteilung kann in Dezilen (Zehntelwerte) erfolgen. Wenn Du 85% oder eine 8,5 erreichst, bist Du gut. In Spotler Activate machen wir etwas ähnliches. Für die Chance „30 Tage kaufen“ kommt Kunde 101 ins zweite Dezil.
Implementiere prädiktive KI in Deinem Marketing
Um personalisierte Aktionen zu planen, kannst Du Vorhersagen nutzen. Kunden mit hoher Kaufbereitschaft können von bestimmten Aktionen ausgeschlossen werden. So gibst Du kein Marketingbudget für Kunden aus, die sowieso kaufen würden.
Beispielsweise wird Kunden mit einer mittleren Kaufwahrscheinlichkeit eine E-Mail mit einer gezielten Produktempfehlung geschickt, während Kunden mit einer geringen Kaufwahrscheinlichkeit ein Rabatt gewährt wird. So erreichst Du die Konversion sehr gezielt. Mehr Umsatz mit weniger Aufwand!
Was sind die Vorteile der prädiktiven KI?
Prädiktive KI hat vier Hauptvorteile:
Kosteneffizienz
Das sollte nach der obigen Erklärung klar sein. Da man mit prädiktiver KI seine Marketingbemühungen sehr genau ausrichten kann, wird weniger Marketingbudget verschwendet.
Verbesserte Effizienz
Mit prädiktiver KI werden Aufgaben wie Segmentierung und Targeting automatisiert. Die Ergebnisse der prädiktiven KI liefern Dir aber auch dann viele Informationen über Kundensegmente, wenn Du diese Aufgaben nicht automatisierst. Denn die Modelle sind probabilistisch. Du verfügst nicht nur über statische Daten, auf die Du Deine Entscheidungen stützen kannst, sondern Du kannst auch das mögliche zukünftige Verhalten vorhersagen.
Mehr Kundenbindung
Mit prädiktiver KI bist Du in der Lage, Deine Kunden in gezielte Kampagnen einzubinden und ihnen ein hochgradig personalisiertes Erlebnis zu bieten. Wer die Bedürfnisse seiner Kunden frühzeitig erkennt, steigert deren Loyalität.
Bessere Entscheidungsfindung
Von prädiktiver KI profitiert nicht nur Deine Datenbank, sondern Dein gesamtes Unternehmen. Denn für strategische Marketingentscheidungen setzt Du fortschrittliche Datenanalysen ein. Mit prädiktiver KI lässt sich jede Entscheidung für oder gegen eine bestimmte Kampagne besser begründen.
Fazit
Prädiktive KI ermöglicht Unternehmen proaktives statt reaktives Handeln, effizientere Prozesse und bessere Ergebnisse. Spotlers Kunden können mit prädiktiver KI Geld sparen und Geld verdienen.